

The Architect(ure)s Behind ChatGPT and Modern Day LLMs

Search for a command to run...
A murder mystery that reveals how neural networks really work
The Riddle that changes everything "If four birds are sitting on a tree and a hunter shoots one bird, how many birds remain on the tree?" When asked this question, do we step directly into the root

AI doesn’t live in clouds, it lives in SIlicon

Everyone's commit history is a mess, you just can't see theirs :)

Why Your "Private" Code May Not Be as Private as You Think

It was November 30, 2022. The general public, minding their own business, was oblivious to the fact that their lives would change. A new paradigm - never seen before. ChatGPT.
"We’ve trained a model called ChatGPT which interacts conversationally," they said. Little did they know, they'd be struggling for the next few months...

It's still pretty surprising that a small research lab(OpenAI) unintentionally built the greatest and most accessible knowledge aggregator ever created and released it without even realizing it.
In August 2015, OpenAI was just an idea articulated over dinner in Menlo Park with Elon Musk, Sam Altman, Ilya Sutskever, Greg Brockman and a handful of others. They’d each come to the dinner with their ideas, but Elon and Sam had a crisp vision of building safe AI in a project dedicated to benefiting humanity.
OpenAI's first office:
OpenAI's office now:


Good fortune dawned upon OpenAI. In early 2017, an unheralded preprint of a research paper appeared, coauthored by eight Google researchers. Its official title was "Attention Is All You Need" which came about to be known as Transformer Paper.
When the transformer paper was released, only a select few, including Ilya Sutskever, recognized its groundbreaking potential. Brockman recalls Sutskever's realization, saying, "When Ilya encountered the transformer, he knew it was the key we had been searching for." The approach was always to persevere with challenges, trusting that either they or someone else in the field would eventually discover the vital piece.
Alec Radford, the mind behind ChatGPT, delved into the transformer architecture. "In two weeks, I achieved more than in the last two years," he states. Radford and his colleagues named their model, an acronym for "generatively pretrained transformer"– GPT-1. This model later became commonly referred to as "generative AI". To develop it, they utilized a compilation of 7,000 unreleased books, primarily from romance, fantasy, and adventure genres, and honed it with Quora Q&As and numerous excerpts from middle and high school exams.
With every new version, GPT showed improvement, largely because each iteration Gobbled an order of magnitude more data than its predecessor. Just a year after launching the initial model, OpenAI rolled out GPT-2, trained on the vast expanse of the internet and boasting an incredible 1.5 billion parameters. As it evolved, its replies became more articulate and precise, to the extent that OpenAI hesitated to release it out in the wild.

A language model (LM) is essentially a probabilistic distribution over sequences of tokens. Suppose we have a vocabulary V of a set of tokens(words). A language model P assigns each sequence of tokens a probability (a number between 0 and 1)
$$x1,…,xL∈V$$
$$p(x1,…,xL)$$
The probability intuitively tells us how “good” a sequence of tokens is. For example, if the vocabulary is V = {ate,ball,cheese,mouse,the}, the language model might assign:
$$p(the,mouse,ate,the,cheese)=0.02$$
$$p(the,cheese,ate,the,mouse)=0.01$$
$$p(mouse,the,the,cheese,ate)=0.0001$$
Mathematically speaking, a language model appears straightforward and elegant. However, this apparent simplicity is misleading: the capability to allocate relevant probabilities to every sequence necessitates profound linguistic skills and extensive knowledge of the world, even if these are implicitly understood.
Come Transformers (Vaswani et al. 2017) - The sequential model that was/is the driving force behind the surge in large language models; It is the foundational architecture many of decoder-only models like GPT-2 and GPT-3, encoder-only models such as BERT and RoBERTa, and encoder-decoder frameworks like BART and T5. A much more detailed explanation - link
Transformers made it possible for a neural net to understand—and generate—language much more efficiently. They did this by analyzing chunks of prose in parallel and figuring out which elements merited “attention.” It allowed these huge neural networks to be trained parallelly without losing context while predicting/interpreting long sequences of text.
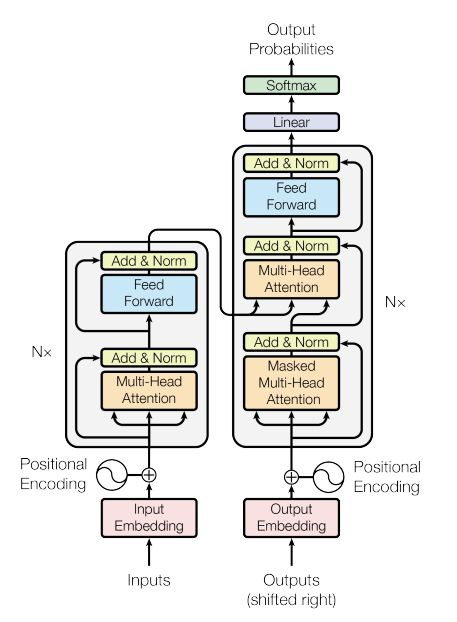
Over time, by training such huge Neural Networks on Trillions of tokens(words) of text, you get very surprising emergent behaviors out of them. This includes the marvelous conversational capabilities of ChatGPT, which is a "Fine Tuned" version of a much bigger language model.
San Fransisco, aka Silicon Valley, was buzzing. "OpenAI unveils its latest model - ChatGPT - A new conversational AI." People were going crazy(still are) with this new-found source of intelligence all just a few words away(prompt). It was mad good. God-like. Almost scary.

ChatGPT became one of the fastest-growing consumer software in history, amassing a reported 100 million users.
Turing test was history, search engines were endangered species, and no college essay could ever be trusted. No job was safe. No scientific problem was immutable. Not anymore.
But there was this one company that had its shovels ready, laces tied up, a smirk on its face - A literal Gold Digger of sorts. Nvidia Corporation (/ɛnˈvɪdiə/ en-VID-ee-ə)
They say "During a gold rush, sell shovels." Only Nvidia had those shovels. Best in class. CUDA was way above ROCm. The A100 GPUs each cost $10,000 and sold out like hotcakes. Large Language Models need GPUs - Like a lot - to run. Running efficient inference was the key for these models. A100s were the best(now beaten by H100s) and the tech giants were hungry.

Many were alarmed including the sleeping giant, Google. Equipped with Google’s Viperfish (TPUv5) ramp, they began full steam ahead launching competitive Conversational Models such as Bard and the much-awaited Google Gemini.
There was a time when you could gaslight ChatGPT into blurting out explicit content given a jailbreaking prompt, but as time went on, OpenAI with some weird techniques called RLHF and others dumbed down the entire thing. You see Intelligence goes hand in hand with the ability to be dangerous.

There was a whole class of researchers and hackers who hated the fact that there was no actual privacy in the conversations they had with ChatGPT. You see OpenAI and others used the data they obtained to further train and better their models. This was a big breach of privacy for people who wanted to use these models over their private/confidential data.
There was this brief thought of running these huge LLMs locally on your computer, given it has sufficient memory/power to fit these models into memory.
Meta launches one of the very first Open Language Models LLaMA. People were now going crazy over the fact that they could have their own ChatGPT like models that they could own! But it still needed a lot of compute aka GPUs to run them.

Enter - Georgi Gerganov - Born and raised in C/C++ land - god tier

Georgi ported LLaMA into C, enabling more efficient inference on these LLMs through 4-bit integer quantization, thus reducing the model's memory footprint. Now all of a sudden you could run these Huge models locally on your small computer!! He along with a few other Open Source Researchers and companies(Huggingface) unleashed this whole new revolution that now shaped the future of these LLMs for the public. It was no longer a moat that only big research labs like OpenAI, Google and Microsoft had. Now, everyday hackers were using these powerful models for various tasks, from gaslighting to generating obnoxious content or writing poetry for their non-existent girlfriends.

Underdogs and anons never heard of before start making headlines. You now have these big research labs(GPU rich) working on huge foundational models with this small set of super smart individuals(yet GPU poor) working in the Open Source ecosystem making wild discoveries every single day. A time where big research organizations and papers discuss, explore and build upon ideas from Reddit comments lol.

It is a golden era - A technological Singularity that a select few people understand the importance of. It's the mechanical calculator —> digital computers era. This is not just another NFT bubble. This is real.
Update: As I was writing this blog, there came Mistral AI
Work at Meta, Deepmind and other top brass labs.
Leave.
Start Mistral AI.
Raise $113 Million seed round within a month of inception.
3 months, 3 founders. Assemble a team, rebuild a top-performance MLops stack, and design the most sophisticated data processing pipeline, from scratch.
Train Mistral 7B - SOTA 7 Billion parameter model - release it to the public via a simple tweet by dumping the magnet link. Absolute Chad.

Though these Language Models are resource-intensive, there are various ultra-optimized ways to run small versions of them on your laptop.
For this small exercise, we will use the Tiny-Stories model and run inference on it. Based on Andrej Karpathy's llama2.c. You can now generate short random stories on your computer!
Make sure you have WSL installed if you are on Windows(It's easier). You can follow the instructions on the llama2.c repo if you are on Mac.
Once inside the WSL, you should find yourself with an interface as shown above in the gif.
First, navigate to the folder where you keep your projects and clone this repository to this folder:
git clone https://github.com/karpathy/llama2.c.git
Then, open the repository folder:
cd llama2.c
Now, let's just run a baby Llama 2 model in C. You need a model checkpoint. Download this 15M parameter model we trained on the TinyStories dataset (~61MB download):
wget https://huggingface.co/Tensoic/Tiny-Stories/resolve/main/model.bin
Compile and run the C code:
make run
./run model.bin
You shall now see a stream of text on your screen being generated. The speed shall depend on your CPU.
On a 12th Gen Intel(R) Core(TM) i9-12900HK, the max I could achieve was a ~360 tokens/sec.
.
.
.
With this, we conclude this blog. Do follow ACM-VIT!
